
Retrieval-Augmented Generation-RAG in LLMs
Introduction to RAG
Retrieval-Augmented Generation (RAG) is a powerful technique that enhances large language models (LLMs) by incorporating external knowledge retrieval.
Unlike traditional LLMs that rely solely on their pre-trained parameters, RAG systems can fetch relevant information from external sources before generating responses, leading to more accurate and up-to-date answers.
The typical RAG workflow consists of:
- Converting documents into vector embeddings and storing them in a database
- Converting user queries into embeddings and finding similar document chunks
- Feeding the retrieved context along with the query to the LLM for generation
To undertand in an over-simplified way: RAG means search the embedding database and assist LLM generate output
Why RAG
Overcomes LLM limitations: Reduces hallucinations by grounding responses in retrieved documents.
Hallucination is one of LLM performance evaluation terms. Non-technically, it means the output of LLM is either false or ground-less.
Dynamic knowledge integration: RAG allows real-time updates to the knowledge base.
One important stage of RAG is updating the knowledge base with up-to-date corpus. A new concept which does not exist before yesterday, or a breaking news in the morning can refresh the knowledge base with new data in a timely manner.
Cost-effective: Avoids expensive model retraining by leveraging external data retrieval.
History and Evolution of RAG
Retrieval-Augmented Generation (RAG) is an advanced AI technique that combines retrieval-based methods with generative models to enhance the accuracy and relevance of AI-generated responses. Here's a brief history of its development:
Pre-RAG Era
Retrieval is relatively new term in LLM world. Traditionally, there was retrieval systems before 2020: Early search engines (e.g., Google, Bing) relied on retrieving pre-existing documents but lacked generative capabilities.
Pure Generative Models like GPT-2 (2019) could generate text but often produced factually incorrect or hallucinated answers.
So, some systems combined retrieval with rule-based generation but at the cost of limited flexibility.
Birth of RAG
At the year of 2020, Facebook AI Research (FAIR) Introduces RAG with the Paper: Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks by Patrick Lewis et al.
The Key Idea here is to combine a neural retriever (e.g., DPR – Dense Passage Retrieval) with a generative model (e.g., BART or T5) which brings an obvious benefit:
- Access to up-to-date external knowledge (unlike static LLMs).
- Reduced hallucinations by grounding responses in retrieved documents.
Evolution and Adoption (2021–Present)
from 2021 onwards, RAG grows fastly in Open-Domain QA with improved fact-based answers by fetching relevant passages before generating answers.
When integrated with Large Language Models like OpenAI’s ChatGPT (2022) and later models (GPT-4), both implicitly use retrieval-like mechanisms, Custom RAG systems can be built on top with enterprise applications (e.g., chatbots, legal/medical QA)
Outlook of RAG
Based on industrial observation and investigation, a few domain requires RAG to achieve faster breakthrough:
- Multi-Modal RAG: Retrieving images, tables, and structured data alongside text.
- Self-Retrieval LLMs: Models that internally decide when to retrieve vs. generate.
- Improved Efficiency: Faster vector databases (e.g., FAISS, Pinecone) and lightweight retrievers.
RAG architecture
A typical RAG pipeline consists of:
| Component | Role | Example Tools |
|---|---|---|
| Retriever | Fetches relevant documents | FAISS, Weaviate, BM25 |
| Embedding Model | Converts text to vectors | all-MiniLM-L6-v2, OpenAI Embeddings |
| Vector Database | Stores and retrieves embeddings | SQLite-VSS, Chroma, Pinecone |
| Generator (LLM) | Produces final response | LLaMA 3, GPT-4, DeepSeek-V3 |
| Reranker (Optional) | Improves retrieval quality | Cohere Reranker, BERT-based rerankers |
A diagram might help you to understand a little bit more, putting these all togher:
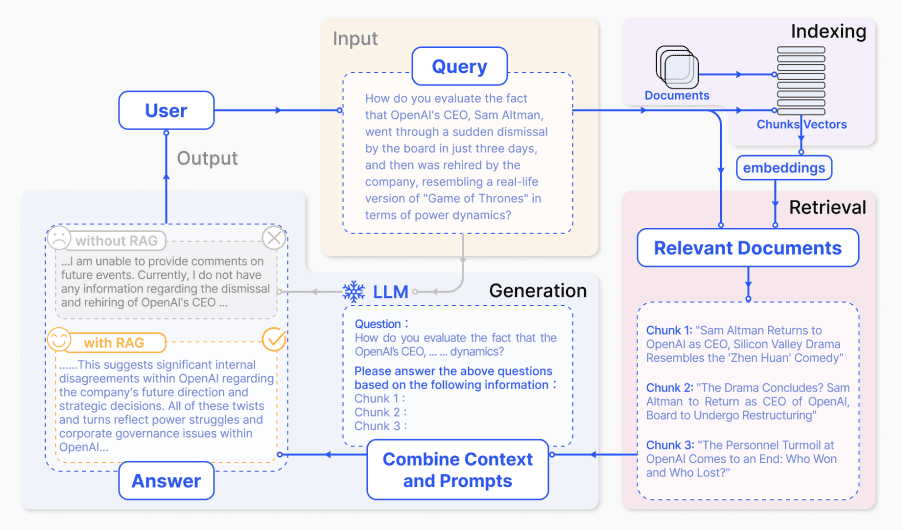
source: Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Overview of RAG architecture
RAG has two vital components:
- Retriever (Dense Passage Retriever - DPR): Given a query , it retrieves relevant documents/passages from a corpus
- Generator (Seq2Seq Model, e.g., BART/T5): Generates an output conditioned on both the query and the retrieved passage .
Mathematically, RAG can be seen as a conditional generation model as:
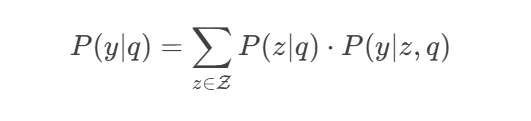 where:
where:
- is the retriever's probability of selecting passage given query .
- is the generator's probability of producing output given and .
The Retriever
The retriever uses two encoders:
- Query Encoder : Maps query to a dense vector .
- Passage Encoder : Maps passage to a dense vector .
The similarity between and is computed using dot product: , where
The probability of retrieving given is given by:
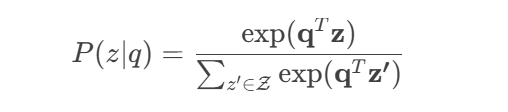
In practice, approximate nearest neighbor search (e.g., FAISS) is used to efficiently retrieve top-k passages .
The Generator
The generator is typically a pre-trained seq2seq model (e.g., BART or T5). Given and retrieved , it generates autoregressively:
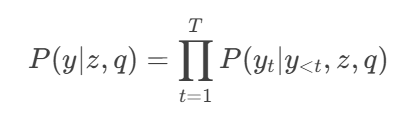
where is the token at step .
For RAG, the generator conditions on both and , often by concatenating them:
Training RAG
RAG is trained end-to-end by optimizing the marginal likelihood:
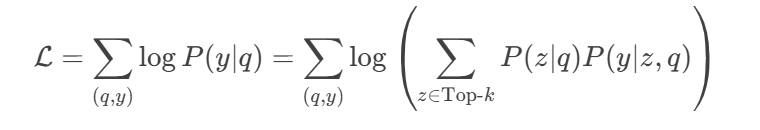
Since summing over all is intractable, we approximate by:
- Retrieving top-k passages .
- Computing the loss using only these passages.
- The gradients are backpropagated through both the generator and retriever.
Inference in RAG
At inference time, RAG generates text by:
- Retrieving Retrieving top-k passages .
- For each , computing using the generator.
- Marginalizing over the retrieved passages:
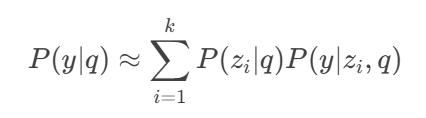
- Decoding using beam search or greedy decoding.
Alternatively, RAG can use "retrieve-then-generate", where only the most relevant passage is used.
Mathematical Formulation of RAG-Token
In the original RAG, the same passage is used for the entire generation (RAG-Sequence). Alternatively, RAG-Token allows different passages to influence different tokens:
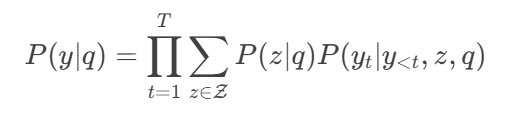 This is more flexible but computationally expensive.
This is more flexible but computationally expensive.
An open domain case
Let us take a look at an example: Open-Domain Question Answering
Query (q):
"What is the capital of France?"
Corpus (𝒵) (Simplified for Illustration):
We have three passages(possible answers) in our retrieval corpus:
- : "France is a country in Europe. Its capital is Paris."
- : "The Eiffel Tower is located in Paris."
- : "Germany's capital is Berlin."
Step 1: Retrieve Relevant Passages
The retriever computes embeddings for the query and passages, then calculates similarity scores (dot product).
Assume the embeddings (extremely simplified for illustration):
- after Query embedding
- as (Passage 1)
- as (Passage 2)
- as (Passage 3)
| Similarity Scores (dot products): |
|---|
We retrieve the top-2 passages (:0.62 and :0.56) and compute the Softmax Probabilities for both:
| Softmax probabilities |
|---|
Step 2: Generate Answers Conditioned on Retrieved Passages
The generator(e.g., BART) produces possible answers for each passage:
- For :
Input: "France is a country in Europe. Its capital is Paris. Question: What is the capital of France?"
Output (): "The capital of France is Paris."
Assume the generator assigns probability: $P(y_1∣z_1,q)=0.9
- For :
Input: "The Eiffel Tower is located in Paris. Question: What is the capital of France?"
Output ():"Paris is the capital of France."
Assume the generator assigns probability:
Step 3: Marginalize Over Retrieved Passages
Combine the retriever and generator probabilities:
Final Probability Distribution over Answers:
"The capital of France is Paris.": 0.4635
"Paris is the capital of France.": 0.3395
The highest-scoring answer is selected:
Output: "The capital of France is Paris."
What happened
Retriever will prioritized (higher similarity) because it explicitly mentions the capital. Generator will assigned higher probability to because is more directly relevant.
The retriever ensures the generator has factual grounding by checking the similarities of questions and passages. So if the question is actually asking about 'Berlin', the passages about Paris might fall out of the top-K
Also The generator rephrases the retrieved knowledge fluently by assigning probability, which is mostly what RAG is trained for.
Evaluating RAG Performance
Evaluating RAG systems requires assessing both retrieval and generation quality. There are plenty metrics used in the industry and we just list some most widely used.
(1) Retrieval Metrics
| Metric | Formula | Description |
|---|---|---|
| Hit Rate (HR@K) | # Correct in Top-K / Total Queries | Measures if the correct doc is in top-K results. |
| Mean Reciprocal Rank (MRR) | 1/rank of first correct doc | Evaluates ranking quality. |
| Recall@K | Relevant docs retrieved / Total relevant docs | Measures coverage of correct answers. |
(2) Generation Metrics
| Metric | Tool/Method | Description |
|---|---|---|
| BLEU, ROUGE | nltk, rouge-score | Compares generated vs reference text. |
| BERTScore | bert-score | Semantic similarity using BERT embeddings. |
| Faithfulness | SelfCheckGPT, FactScore | Checks if the output aligns with retrieved docs. |
| LLM-as-a-Judge | DeepSeek , GPT-4 | Uses an advanced LLM to score response quality. |
RAG demonstration
We will walk through a real but simplified RAG demo, using lightweighted FAISS & SQLite
Step1 Pinecone index creation
please go to :Pinecode to sign up and generate an api_key
Then create a serverless embedding index with the following codes:
!pip install pinecone
from pinecone import Pinecone, ServerlessSpec
pc=Pinecone(api_key='pcsk_7CWjnv_95ua7UZZXtjMqwJEuDshYxiQ6JuKD184tkuxXAQZ5N1ByVW8GhGgSAUN6VBXJ8k')
index_name = "rag-demo"
pc.create_index(
name=index_name,
# model_name="sentence-transformers/all-mpnet-base-v2", it need 768 dimension
dimension=768,
metric="cosine",
spec=ServerlessSpec(
cloud="aws",
region="us-east-1"
)
)
- we create an index called 'rag-demo' for data storage
- we define the dimension number in alignment with the embedding model
- we define the similiarity search method as consine
Step2 Define document processing functions
For illustration purpose, we feed our in-hand data
def load_sample_documents():
"""Create sample documents if you don't have web URLs"""
docs = [
Document(
page_content="Retrieval-Augmented Generation (RAG) combines retrieval from a knowledge source with text generation.",
metadata={"source": "internal_knowledge"}
),
Document(
page_content="RAG systems first retrieve relevant documents then use them to inform the generation process.",
metadata={"source": "internal_knowledge"}
)
]
return docs
def chunk_documents(documents):
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=100
)
return text_splitter.split_documents(documents)
- We split our text into chunks of size 500
- To overlap adjacent chunks so they can remember the context
Step3 Vector setting
import os
import pinecone
from langchain.embeddings import HuggingFaceEmbeddings
from langchain_pinecone import PineconeVectorStore
from langchain.schema import Document
from langchain.text_splitter import RecursiveCharacterTextSplitter
import pandas as pd
from tqdm import tqdm
def setup_vector_store(documents, index_name="rag-demo"):
embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/all-mpnet-base-v2"
)
index = pc.Index(index_name)
vectorstore = PineconeVectorStore(
index, embeddings)
vectorstore.add_documents(documents)
return vectorstore
document=load_sample_documents()
document_chunk=chunk_documents(document)
# define vector store, then feed data
vectorstore=setup_vector_store(document_chunk)
- We use PineconeVectorStore from langchain to set up a vector store with index name and embedding model
- we invoke add_documents of vector store to upsert the corpus chunks
Step4 RAG retrieval and generation
We will define a question, and retrieve the contexts the question will fit in. After that, we use deepseek to generate the response, given both questions and contexts
!pip install openai
from openai import OpenAI
deepseek_key= 'sk-133b8431964e407fb8e1b0768fa0ebad'
client = OpenAI(api_key=deepseek_key, base_url="https://api.deepseek.com")
def llm_generate(prompt,temperature=0.7):
messages=[{"role": "user", "content": prompt}]
response = client.chat.completions.create(
model="deepseek-chat",
messages=messages,
temperature=temperature,
stream=False)
return response.choices[0].message.content
def generate_answer(question, context):
prompt = f"""Answer the question based on the context below.
Context:
{context}
Question: {question}
Answer:"""
return llm_generate(prompt)
def rag_query(question, vectorstore, k=3):
"""Perform RAG query using DeepSeek as LLM"""
# Retrieve relevant documents
docs = vectorstore.similarity_search(question, k=k)
context = "\n\n".join([doc.page_content for doc in docs])
# Generate answers with context and questions
answers = generate_answer(question, context)
# Query DeepSeek
return question, answers, context
question="What is RAG and how does it work?"
question, answers, context=rag_query(question, vectorstore)
- llm_generate for response generation
- generate_answer will generate the prompt with questions and answers, then invoke the model directly
- rag_query puts all together, and retrieves the contexts at the start of the function
Step5 Evaluate the RAG performance
We will use DeepSeek to assign scores to the RAG for some important categories
def evaluate(question, answer, context):
prompt = f"""Evaluate this QA pair (1-5 scale):
Question: {question}
Answer: {answer}
Context: {context}
Score these aspects:
1. Relevance (answer matches question)
2. Accuracy (facts correct per context)
3. Completeness (fully answers question)
4. Clarity (well-structured response)
Provide scores as: Relevance: X, Accuracy: Y, Completeness: Z, Clarity: W"""
evaluation = llm_generate(prompt)
return evaluation
text=evaluate(question, answers, context)
'''
Below are the output from the LLM as a judge
Here’s the evaluation of the QA pair:
- **Relevance: 5** (The answer directly addresses the question, explaining both what RAG is and how it works.)
- **Accuracy: 5** (The facts align perfectly with the provided context and general understanding of RAG.)
- **Completeness: 5** (The answer covers both retrieval and generation, fully answering the question.)
- **Clarity: 5** (The response is well-structured, concise, and easy to follow.)
**Scores:** Relevance: 5, Accuracy: 5, Completeness: 5, Clarity: 5
'''
def reg_parse(line):
pattern = r'- \*\*(.*?): (\d+)\*\* \((.*?)\)'
match = re.search(pattern, line)
if match:
return match.group(1),match.group(2),match.group(3)
else:
return None,None,None
eval_result=[]
def parse_evaluation(text):
print(text)
for line in text.split("\n"):
if ":" in line:
key, value, reason =reg_parse(line)
if(key != None):
eval_result.append({"cat":key.strip().lower(), "score":float(value.strip()),"reason":reason})
parse_evaluation(text)
print("\n",pd.DataFrame(eval_result))
- based on the RAG output, we use regexp to parse the category, score and reason it line by line
- create a list of dictionary and print it as dataframe
- This evaluation is called "LLM as a judge", a popular method for groundless response.
RAG vs Fine-tuning
Retrieval-Augmented Generation (RAG) and fine-tuning are both two powerful techniques for enhancing Large Language Models (LLMs). While both aim to improve model performance, they differ significantly in approach, implementation, and use cases.
Below is a detailed comparison for reference.
Core differences Between RAG and Fine-tuning
| Feature | Retrieval-Augmented Generation (RAG) | Fine-Tuning |
|---|---|---|
| Knowledge Update | Dynamic (real-time retrieval) | Static (requires retraining) |
| Implementation | External database + retrieval | Model weight adjustments |
| Cost | Lower (no full model retraining) | Higher (compute-intensive) |
| Scalability | Easily scales with new data | Limited by model capacity |
| Hallucination Control | Better (grounded in retrieved docs) | Depends on training data |
| Latency | Slightly higher (retrieval step) | Lower (direct inference) |
| Best For | Dynamic knowledge, fact-heavy tasks | Style adaptation, domain specialization |
When to Use RAG vs Fine-Tuning
Use RAG When:
- You need up-to-date information (e.g., news, research papers).
- Your knowledge base changes frequently (e.g., customer support docs).
- You want to reduce hallucinations (retrieved docs act as evidence).
- You lack sufficient training data (RAG doesn’t require fine-tuning data).
Use Fine-Tuning When:
- You need stylistic control (e.g., legal, medical tone).
- The task requires deep domain adaptation (e.g., coding assistants).
- Low-latency responses are critical (no retrieval step).
- You have high-quality labeled data (for supervised fine-tuning)
Author: Jun Ma, co-founder of obserpedia