Unlock the power of AI-Part II
Smarter and Faster Language Models
In the world of artificial intelligence, Large Language Models (LLMs) like GPT, LLaMA, and Deepseek have taken center stage. These models can write essays, answer complex questions, and even generate code. But behind their impressive capabilities lies a challenge: they’re often massive, resource-hungry, time-bombing systems that require powerful hardware(GPU intensive computers) to run.
This is where techniques like distillation and fine-tuning come into play. These methods not only make LLMs more efficient but also tailor them to specific tasks, unlocking their full potential for real-world applications.
If you’ve ever wondered how AI can be made faster, smaller, and more specialized, this article is for you. We’ll break down these concepts in a way that’s easy to understand, without diving too deep into technical jargon.
We have covered distillation in part i and in this part, Let’s explore how fine-tuning are shaping the future of AI and how distillation and fine-tuning can work together to make better.
What is Fine-Tuning
While distillation focuses on making models smaller, fine-tuning is all about making them smarter in specific areas. Imagine you have a general-purpose assistant who’s good at many things but not an expert in any one thing. Fine-tuning is like giving that assistant specialized training to excel in a particular field.
In the context of LLMs, fine-tuning involves taking a pre-trained model (which has already learned general language patterns) and training it further on a specific dataset just to make it more capable in the area this dataset is sourced from. This could be anything from medical journals to legal documents, depending on the desired application. The result is a model that’s highly skilled in that particular domain.
Why Fine-Tune
Fine-tuning is particularly useful because it leverages the general language understanding capabilities of the pre-trained model while adapting it to the nuances of a specific task. This approach is more efficient than training a model from scratch, as it requires less computational resources and time
Efficiency
Training large language models from scratch requires enormous computational resources and time. Fine-tuning leverages the pre-trained model's existing knowledge, significantly reducing the amount of data and computational power needed to achieve high performance on specific tasks.
Performance
Pre-trained models have already learned a vast amount of general language knowledge. Fine-tuning allows these models to specialize in a particular task, often leading to superior performance compared to models trained from scratch on the same task.
Adaptability
Fine-tuning enables the adaptation of a single pre-trained model to multiple tasks. This flexibility is particularly valuable in real-world applications where a model may need to perform various functions, such as text classification, translation, and summarization.
Data Efficiency In many domains, labeled data is scarce and expensive to obtain. Fine-tuning allows for effective learning even with limited data, as the model can leverage the general knowledge acquired during pre-training.
Transfer Learning
Fine-tuning is a form of transfer learning, where knowledge from one domain (the pre-training domain) is transferred to another (the fine-tuning domain). This transfer of knowledge can lead to better generalization and performance on the target task.
History of Fine-Tuning
The concept of fine-tuning has its roots in transfer learning, a technique that has been widely used in machine learning for decades. Transfer learning involves taking a model trained on one task and reusing it on a different but related task.
Fine-tuning is a specific form of transfer learning where the pre-trained model is adjusted slightly to better fit the new task. In the early days of machine learning, fine-tuning was primarily used in computer vision tasks.
For example, a model trained on a large dataset like ImageNet could be fine-tuned on a smaller dataset of medical images to improve its performance in diagnosing diseases.
With the advent of deep learning and the development of large-scale language models like BERT, GPT, and T5, fine-tuning has become a standard practice in natural language processing (NLP). These models, which are trained on massive amounts of text data, can be fine-tuned on specific tasks with relatively small datasets, achieving state-of-the-art performance across a wide range of NLP applications.
Real-World Applications of Fine-Tuning
Fine-tuning has been successfully applied in numerous real-world applications, demonstrating its versatility and effectiveness. Here are a few notable examples:
Sentiment Analysis
Fine-tuning LLMs on sentiment analysis tasks allows businesses to automatically classify customer reviews, social media posts, and other text data as positive, negative, or neutral. This is particularly useful for companies looking to gauge public opinion about their products or services.
Machine Translation
Fine-tuning models like Google's Transformer on specific language pairs can significantly improve translation quality. For instance, a model pre-trained on a large multilingual corpus can be fine-tuned on a smaller dataset of English-to-French translations to produce more accurate and fluent translations.
Question Answering
Fine-tuning LLMs on question-answering datasets enables the development of intelligent systems that can answer user queries based on a given context. This is widely used in virtual assistants, customer support chatbots, and educational tools.
Medical Text Analysis
In the healthcare industry, fine-tuning LLMs on medical texts can help in tasks like diagnosing diseases from clinical notes, extracting relevant information from medical literature, and even predicting patient outcomes.
Legal Document Analysis
Fine-tuning models on legal documents can assist in tasks such as contract analysis, legal research, and case law prediction. This can save legal professionals significant time and effort.
Fine-Tuning in nutshell
How Fine-Tuning Works
Fine-tuning can be understood mathematically as an optimization problem. Let's break it down step by step:
Pre-Trained Model
Let f(θ) be a pre-trained language model with parameters θ . This model has been trained on a large corpus of text data to minimize a loss function , which could be a cross-entropy loss for language modeling:
 where:
where:
- is the input text,
- is the target token,
- is the number of tokens in the training data.
Fine-Tuning Objective
When fine-tuning, we adapt the model to a new task with a smaller dataset .
The goal is to minimize a new loss function specific to the task:
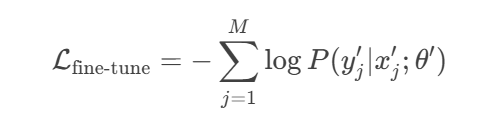 Here, represents the updated parameters of the model after fine-tuning.
Here, represents the updated parameters of the model after fine-tuning.
Optimization
Fine-tuning involves optimizing the parameters to minimize . This is typically done using gradient descent or one of its variants (e.g., Adam, RMSprop). The update rule for the parameters can be written as:
where
- is the learning rate,
- is the gradient of the loss with respect to the parameters.
Regularization
To prevent overfitting to the small fine-tuning dataset, regularization techniques such as dropout, weight decay, or early stopping are often employed. For example, weight decay adds a penalty term to the loss function:
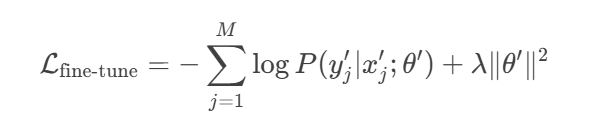
where is the regularization strength.
Learning Rate Scheduling
In practice, the learning rate is often adjusted during training using a learning rate scheduler. This helps in converging to a better minimum and can be expressed as: where:
- is the initial learning rate,
- is the current training step, and
- is a function that decreases the learning rate over time and tailors other learning properties well.
Surely, you can define you own learning rate decay as we will show in the later codes snippets
Fine-Tuning Process
The fine-tuning process can be summarized as follows:
- Step1: Initialize the model with pre-trained parameters .
- Step2: Compute the loss on the fine-tuning dataset.
- Step3: Update the parameters using gradient descent: .
- Step4: Repeat steps 2-3 until convergence or a stopping criterion is met.
Here are the codes for the fine-tuning
!pip install datasets
from transformers import DistilBertForSequenceClassification, DistilBertTokenizer
import torch
import torch.nn as nn
import torch.nn.functional as F
# Load student model (DistilBERT)
student_model = DistilBertForSequenceClassification.from_pretrained("distilbert-base-uncased")
student_tokenizer = DistilBertTokenizer.from_pretrained("distilbert-base-uncased")
from datasets import load_dataset
# Load the rotten_tomatoes dataset
dataset = load_dataset("rotten_tomatoes")
train_data=dataset['train']
val_data=dataset['validation']
test_data=dataset['test']
- We reuse our distilbert-base-uncased as starting point
- Use built-in dataset rotten_tomatoes, a dataset with movie review as feature and 0 or 1 as movie label
- The data set is already split into training, validation and test data
We do some preparation then:
def tokenize_data(dataset, tokenizer):
texts = [example["text"] for example in dataset]
labels = [example["label"] for example in dataset]
encodings = tokenizer(texts, truncation=True, padding=True, return_tensors="pt")
return encodings, torch.tensor(labels)
# Tokenize with student tokenizer
student_encodings, student_labels = tokenize_data(train_data, student_tokenizer)
from torch.utils.data import DataLoader
# Create DataLoader(the index limitation is just to avoid the storage limit error)
train_dataset = torch.utils.data.TensorDataset(student_encodings["input_ids"], student_encodings["attention_mask"], student_labels)
train_loader = DataLoader(train_dataset, batch_size=16, shuffle=True)
from torch.optim import AdamW
from transformers import get_scheduler
import torch.optim as optim
# Define Loss function for pre-trained model
def kl_loss(student_logit, hard_labels):
return F.cross_entropy(student_logit, hard_labels)
#set intial loading rate, and use AdamW as optimizer
initial_lr=5e-5
optimizer=AdamW(student_model.parameters(), lr=initial_lr)
#compute the steps for learning rate decay later one in codes
num_epochs = 3
num_training_steps = num_epochs * len(train_loader)
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps
)
- We define a tokenization function tokenize_data with dataset and tokenizer as inputs
- We get token list from the movie reviews
- We encapsulate data into a loader container along with other properties like batch_size and shuffling setting
- We define the loss function, initial learning rate and use AdamW as optimization method
- Most importantly, we computes the number of the total forward pass for learning rate decay later on
Finally, let us do tuning:
#for progressive tracking bar
from tqdm import tqdm
for epoch in range(num_epochs):
student_model.train()
total_loss=0
#learning rate will get smaller for each epoch
lr=initial_lr*(1-epoch/num_epochs)
for param_group in optimizer.param_groups:
param_group['lr']=lr
for batch in tqdm(train_loader, desc=f"Epoch {epoch+1}"):
input_ids=batch[0]
attention_masks=batch[1]
student_labels=batch[2]
#forward pass
#sentences will have paddings. Most of time, attention_mask will be like [1,1,1...0,0]
#0 here will be mask to remove the "attention" to meaningless padding
outputs = student_model(input_ids=input_ids, attention_mask=attention_masks)
student_logits=outputs.logits
loss=kl_loss(student_logits, student_labels)
total_loss+=loss.item()
#back propagation
loss.backward()
# Update weights
optimizer.step()
optimizer.zero_grad()
avg_loss = total_loss / len(train_loader)
print(f"Epoch {epoch + 1}, Loss: {avg_loss}")
Please note the code snippets below:

Learning rate will become smaller and smaller when epoch elapse. It is extremely useful to manipulate the training rate if you:
- Write your own learning rate decay logic
- Put the decay logic and assign to parameters in different places or loops if you want to more fine-grained control
A few additional notes when you do the fine-tune while keeping the knowledge learned in the pre-trained model
- Start with a small learning rate
- Try to inject a few general data samples
The Different Types of Fine-tuning
As fine-tuning evolves in the span of different industries, application, domains and area, fine-tuning is now handled in a variety of ways, based on the primary focus and specific goals.
Supervised Fine-tuning: The most simple and popular fine-tuning method. The model is trained using a labeled dataset relevant to the goal task, such as text categorization or named entity recognition.
Few-shot Learning: Collecting a large labeled dataset is not always practical. Few-shot learning addresses this by including a few samples (or shots) of the required task at the start of the input prompts. This allows the model to better understand the problem without requiring substantial fine-tuning.
Transfer Learning: Although all fine-tuning approaches are a kind of transfer learning, this category is explicitly designed to allow a model to execute a task other than the one it was initially trained on. The fundamental idea is to use the model’s knowledge gathered from a large, general dataset to solve a more specific or related problem.
Domain-specific Fine-tuning: This form of fine-tuning aims to train the model to understand and generate content specific to a given domain or industry. The model is fine-tuned using a dataset of text from the target domain to increase its context and understanding of domain-specific tasks.
However, these ways of fine tuning are not mutually exclusive. As demonstrated above in our example, we are actually doing supervised fine-tuning while specific to movies sentitivity analysis.
Challenges and Limitations
Fine-tuning an LLM for a specific task or set of information is a powerful technique, but it comes with significant downsides.
Cost and Time: Training large models requires substantial computing power. Smaller teams or those with limited budgets may find these costs prohibitive.
Brittleness: Fine-tuned models may struggle to adapt to new data without expensive retraining. They can become locked into a “stabilized snapshot” of their training data.
Expertise Required: Building and maintaining AI systems requires specialized skills and knowledge, which can be hard to acquire.
Stunning Outputs: Models can sometimes “visualize” unexpected or biased results, or forget previously learned information. Ensuring their accuracy is an ongoing challenge.
In short, while fine-tuning is a powerful process, it requires careful management. We need find way to ensure the benefits outweights the cost
How Do Distillation and Fine-Tuning Work Together
In Unlock the power of AI-Part I, we discuss the distillation method to help student model learn from a much bigger teacher model, now the basic idea is: can we use distill to get a smaller, more efficient model while still tuning it to address specific type of tasks?
The answer is Yes.
Distillation and fine-tuning are often used in tandem to create models that are both efficient and specialized. Here’s how they complement each other:
- Start with a Large Model: Begin with a powerful, general-purpose LLM like GPT-4.
- Fine-Tune for Specificity: Train the model on a specialized dataset to make it an expert in a particular domain.
- Distill for Efficiency: Create a smaller, distilled version of the fine-tuned model that retains its specialized knowledge but is easier to deploy.
For example, a company might fine-tune GPT-4 on customer service data to create a chatbot for their website. Then, they could distill this fine-tuned model to make it run efficiently on their servers without sacrificing performance.
Real-World Applications with distillation and fine-tune combined
The combination of distillation and fine-tuning has opened up a world of possibilities for AI applications. Here are a few examples:
Healthcare
Distilled and fine-tuned models can assist doctors by summarizing medical records, suggesting treatments, or even predicting patient outcomes.
Education
Smaller, specialized models can help students with personalized learning, answer questions about specific subjects, or even grade assignments.
Customer Support
Fine-tuned chatbots can handle customer inquiries more effectively, while distilled versions ensure quick responses and reduce operational costs.
Creative Industries
Writers and marketers can use fine-tuned models to generate content tailored to specific audiences, while distilled versions make these tools accessible on everyday devices.
Conclusion
Imagine a future where every smartphone has a personal AI assistant that’s not only fast and efficient but also tailored to your specific needs. Whether you’re a doctor, a teacher, or a creative professional, distilled and fine-tuned models could revolutionize the way you work.
LLM distillation and fine-tuning are more than just technical buzzwords—they’re transformative techniques that bring the power of AI to the masses. By making models smaller, faster, and more specialized, these methods enable a wide range of applications that were once out of reach.
Whether you’re a developer looking to build the next big AI tool or simply someone curious about how AI works, understanding distillation and fine-tuning is key to appreciating the incredible potential of modern language models. As AI continues to evolve, these techniques will ensure that it remains not only powerful but also practical and accessible for everyone.
For Unlock the power of AI-Part I
Author: Jun Ma, co-founder of obserpedia